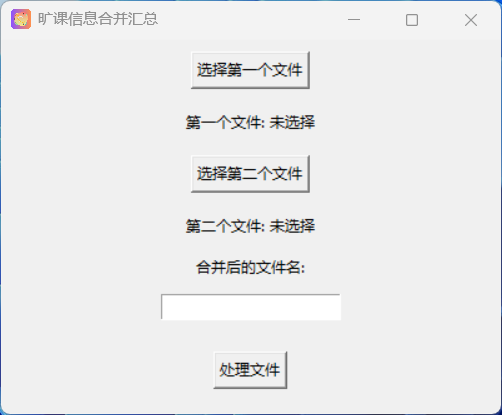
24建筑工程学院学习部旷课汇总程序点击下方下载1.3 Setup.exe 旧版
1.4 Setup-MbkG.exe 最新版,修复了25届部分班级无法添加的bug
如果需要源码请联系我~
24建筑工程学院学习部旷课汇总程序 点击下方下载 1.3 Setup.exe 旧版 1.4 Setup-MbkG.exe 最新版,修复了25届部分班级无法添加的bug 如果需要源码请联系我~